Jos lyö sitkeästi päätä seinään, niin pää ei välttämättä hajoa vaan seinään tulee reikä. Alun takkuamisen jälkeen solahdin mukavaan
flow-tilaan uuden Arena-verkkokirjaston rakentelussa. Ja sitten tökkäsi: vuosikausia taustalla pyyteettömästi raksutellut verkkokirjaston palvelin rikkoontui. Syy ei ollut löytynyt tällä erää tästä työpisteestä, vaan konesalimuutosta, joissa palvelin jouduttiin sammuttamaan. Tämän jälkeen se ei enää halunnut käynnistyä. Olisi pitänyt tietää: jos se toimii, älä koske siihen.
Jouduin siis koskemaan jälleen kirjastojärjestelmän vaatimusmäärittelyyn. Pieni tauko ja etäisyys oli ollut asialle vain hyväksi: katselin määrityksiä uusin silmin ja kurtistuvin otsin, ja kohta sai Excelin etsi-korvaa-toiminto töitä.Muistinvirkistys ja tietojen päivitys tulikin tarpeeseen, sillä edessä oli matka Helsinkiin, missä UKJ:n eli
Uuden kirjastojärjestelmän suunnittelun kakkosvaihe pistettiin kunnolla käyntiin 6.6. Paikalle oli saapunut kokoussalillinen ammattilaisia, etänä verkossa tilaisuutta seurasi ilmeisesti reilut sata henkeä.
UKJ-hanke sai OKM:ltä tälle vuodelle hakemansa avustuksen, jolla hankkeeseen on palkattu kehittämispäällikön lisäksi 5 asiantuntijaa. Työtä valvomaan on asetettu
ohjausryhmä ja Kansalliskirjaston
projektinhallintaryhmä. Ensimmäisen vaiheen kirjastojen edustajista koottuja työryhmiä on yhdistelty ja jäljellä on nyt neljä suunnittelun
asiantuntijaryhmää.
Tämän vuoden aikana hankkeessa keskitytään tarkentamaan kirjastojärjestelmän määrityksiä sekä laatimaan projektisuunnitelma, missä määritellään toteutuksen tapa ja vaiheistus. Määrityksiä jatketaan
kokonaisarkkitehtuurin pohjalta siten, että suunnittelun asiantuntijaryhmät keskittyvät tieto- ja toiminta-arkkitehtuurin kuvauksiin ja hankkeeseen palkatut asiantuntijat vastaavat tietojärjestelmä- ja teknologia-arkkitehtuurien suunnittelusta.
Asiantuntijaryhmissä on yhteensä 54 edustaajaa neljästä eri kirjastosektorista, joista yleisten kirjastojen edustajia on 8. Työ tapahtuu pääasiassa etäpalavereina ja sähköpostilla. Jotta UKJ:ssa saataisiin oikeasti myös yleisten kirjastojen ääni kuuluville, olisi yleisten kirjastojen edustajien määrää saatava vielä kasvatettua. Mukaan luvattiin ottaa kaikki halukkaat ja jälki-ilmoittautuneet, joten jos tiedät jotain kirjastojen toiminnasta ja haluat vaikuttaa uuden järjestelmän suunnitteluun, tule mukaan porukkaan! Asiantuntijaryhmien (ja koko UKJ:n) toimintaa voi myös seurata hankkeen wikissä, minne voi jättää kommentteja koko prosessin ajan.
UKJ:n pohjaratkaisu tulee olemaan
avoimeen lähdekoodiin perustuva modulaarinen kokonaisuus, joka integroituu muuhun kansalliseen palvelukokonaisuuteen. UKJ:n luetteloinnin ja tietokannan perusta tulee olemaan
Melinda ja verkkokirjastona toimii
Finna.
UKJ:n kehittämisessä tullaan käyttämään
ketteriä menetelmiä, joista seminaarissa oli kertomassa Celkee OY:stä Sami Lempinen.
Ketterä kehitys on erityisesti it-hankkeisiin suunnattu menetelmä, jossa kehittäminen tapahtuu sykleittäin. Uutta julkaistaan säännöllisesti ja nopeasti ja virheet voidaan korjata heti kehittämisen ollessa käynnissä.
Valittuun menetelmään kuuluvat osaltaan käyttäjäkertomukset, joissa kuvataan mitä käyttäjä - it-tuki, kirjastovirkailija, asiakas - tekee, esim. " Asiakkaana haluan päättää, saanko lainauksestani kuitin paperisena vai sähköpostiini". Lähtökohta ei siis alkuvaiheessa vielä ole: järjestelmä tekee jotain, tai vielä pahemmin: järjestelmän on tehtävä jotain juuri näin.
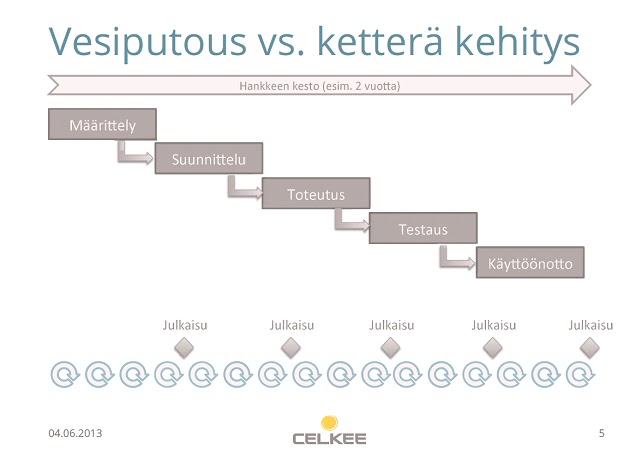
Verrattuna perinteisempään
vesiputousmalliin ketterillä menetelmillä on tutkimustenkin mukaan todennäköisyys epäonnistua pienempi. Perinteinen it-ohjauksen malli on ns. vesiputousmalli, jossa projektin eri vaiheet seuraavat toisiaan kuvan osoittamalla tavalla. Mikäli tässä mallissa huomataan vasta testaus - tai peräti julkaisuvaiheessa, ettei ohjelma toimi, on prosessissa palattava pitkä askelma taaksepäin.
Kuva: Sami Lempinen, Celkee Oy
Ketterässä mallissa kehittäminen tapahtuu iteraatioissa eli sykleissä, joiden jälkeen kehitettyä toimintoa katselmoidaan ja se joko hyväksytään tai palautetaan kehittelyyn - tai huomataan ettei toiminnolla ole oikeasti mitään käyttöä, ja se voidaan poistaa ohjelmasta kokonaan. Toisin kuin fyysisten esineiden, esim. talon rakentamisessa, onnistuneessa it-projektissa lähtökohta on vaikeissa kysymyksissä, talonrakennuksessa ainakin maallikko katsoo kuvastosta kivannäköisen mallin ja miettii vasta myöhemmin miten sähköpistokkeet laitetaan. UKJ:n kaltaisessa it-projektissa aluksi on selvitettävä miten yhteydet Melindaan ja Finnaan saadaan rakennettua, sillä jos näissä möhlitään, ei kivalla ulkoasulla ja näppärillä kilkkeillä kirjastossa pyöri muu kuin it-päällikkö pitkinä unettomina öinä pakoreittejä pohtien. Ja silloin kannattaa siirtyä telkkarin ääreen ja pistää pyörimään
Piin elämä.